
Android 开发总结笔记(三) - Java 集合总结
Java 集合总结
Java 有哪些集合,继承关系是怎么样的
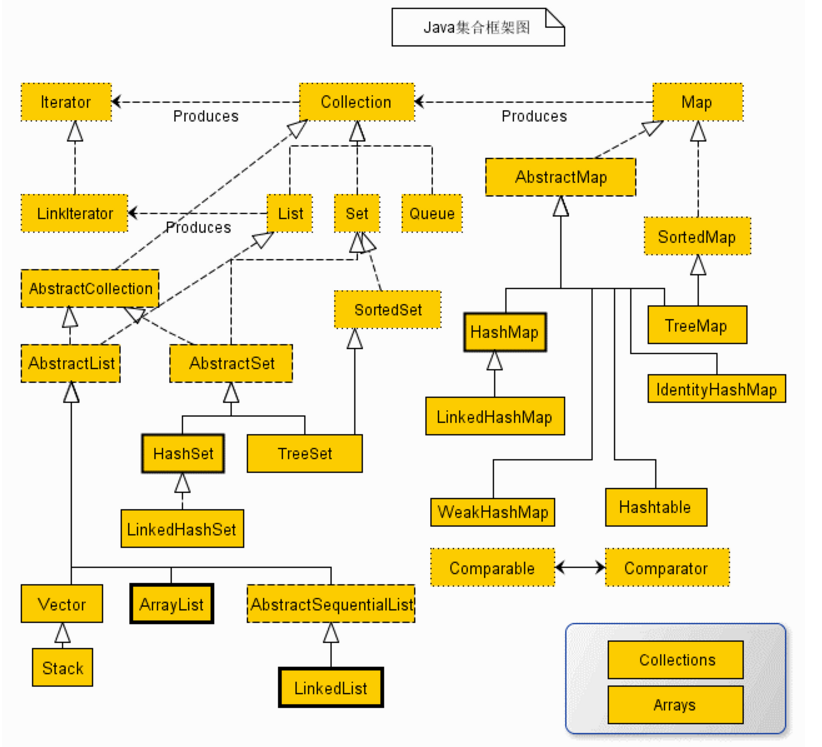
平时常用的集合有哪些
- Collection
- List 可以重复添加元素
- ArrayList
- LinkedList
- Set 不能重复添加元素
- HashSet 不接受 null
- TreeSet
- Queue
- Deque
- PriorityQueue 数组实现,堆
- ArrayDeque 数组实现, 2 个游标
- List 可以重复添加元素
- Map 以键值对的形式保存值
- HashMap
- LinkedHashMap
- TreeMap
- Hashtable
- HashMap
List
ArrayList
数组实现,初始容量为 10,不够的时候扩容,扩容就是数组在当前长度基础上增大一倍。添加数据的时候,先判断容量是否够,不够就扩容,扩容完成后再添加。
缺点: 线程不安全
LinkedList
链表实现。尾插法,即新节点插入到链表尾部。
Set
HashSet
Java 1.8 底层基于 HashMap 实现,HashMap 的 value 都是同一个对象。
TreeSet
Java 1.8 默认是 TreeMap 实现,也可以给构造方法传入一个 NavigableMap(接口) 的实现实例。
Queue
Deque
双端队列,
PriorityQueue
堆,数组实现的
ArrayDeque
Map
HashMap
最常用的一种结构,以数组为基础,数组元素为链表的复合结构。
需要注意的是:
初始容量为 16,默认承载因子为 0.75 ,需要注意的是,在指定容量的时候,如果不是 2 的指数,会计算一个大于指定容量,但是同时又是符合要求里面最小的一个 2 的指数作为容量。
当元素个数大于或等于(当前容量 * 承载因子),就会扩容。
Java 1.7 插入数据的时候是头插法,即新的节点在链表头部。Java 1.8 及以后是尾插法,即新的节点在链表尾部。这个修改是为了解决扩容的时候可能会发生的死循环的问题。
Java 1.8 及以后,当同一个链表元素个数大于等于 (8 - 1) 的时候,会变成红黑树来存储,目的是提高效率。红黑树的转变是先比较 key 的 hash 大小,如果相同就尝试比较 key 自身。
无论是扩容,还是转成红黑树,都是先把节点放进去后再做扩容或者转换。
hash 碰撞,是指不同的 key, key 的 hash 和数组大小再次计算后,得出的索引一致。 hash 碰撞越少,HashMap 的效率越高。1.7 和 1.8 hash 算法有区别。
LinkedHashMap
基于 HashMap 实现的,同时还是一个双向循环链表(比 HashMap 的节点多了个 before 和 after 指针),在开启排序的情况下,最近使用过的节点(put、get)会放在链表尾部。
这个特性很适合 LRU 算法的实现,大概原理就是 LinkedHashMap 开启排序,然后最近使用的元素都在链表尾部,当链表长度大于指定长度的时候,就从链表头部开始删除,因为链表头部是最近没有使用的。
Hashtable
synchroinzed 实现线程安全,效率低下。
TreeMap
TreeMap 在 Java 1.8 底层实现是一个红黑树,排序的规则是比较 key 的 “大小”。并且要求 key 的类型是需要可以比较的,并且 key 值不能为 null。
和 HashMap 一样,先插入数据,然后在重排序。
碰到的常见问题
线程安全问题
由于以上的都不是线程安全的,所以多线程的时候容易出问题,对于安全的线程有以下的几种
- List
- Vector 通过方法添加
synchizoned关键字实现,效率低下。 - CopyOnWriteArrayList 每次
写(添加,删除,修改)的时候,都会生成一个新副本,所以频繁的写操作会消耗大量内存。
- Vector 通过方法添加
- Set
- CopyOnWriteArraySet 类似 CopyOnWriteArrayList
- Map
- ConcurrentHashMap Java 1.7 是通过分段锁实现,Java 1.8 是
CAS和synchroinzed实现
- ConcurrentHashMap Java 1.7 是通过分段锁实现,Java 1.8 是
ConcurrentHashMap
分段锁来实现,分段锁可以提高效率,是因为如果不同线程的读写发生在不同的段上,实际上是没有锁竞争的,也就是没有线程被阻塞,所以效率高。
Java 1.7 及以前实现原理
ConcurrentHashMap 有一个 segments 数组,这个数组元素的类型是 Segment,它继承自 ReentrantLock ,也就是说 Segment 是一个锁。
ConcurrentHashMap 插入或者修改数据的时候,会先找到是哪一个 segment , 然后在这个 segment 上面插入或者修改数据,而 segment 插入或者修改数据的时候,会先尝试获取锁,如果获取失败,说明有锁竞争,然后先尝试自旋,自旋超过次后,就开始阻塞线程。因此是线程安全的。
另外需要注意的是获取数据的时候没有加锁,因为是 volatile 变量,可以拿到最新的数据,但是呢,
Java 1.8 及以后实现原理
类似 HashMap ,放弃了分段锁,在插入或者修改数据的时候利用 cas 和 synchionzed 来保证线程安全,大概的原理就是先利用 cas 来设置,设置失败的时候说明有线程竞争,这个时候就用 synchionzed 来加锁,保证线程安全。
Java 1.8 之后,为何放弃了分段锁
分段后,数据不连续,碎片较多,内存浪费严重,扩容等操作耗费大量的时间。
Java 1.8 是用的 synchornized + HashMap 来做的, synchornized jvm 层做了优化,同时 HashMap 也做了红黑树的优化,所以效率方面有保障。
主要方法总结
List 接口
- add(E):boolean
- add(int, E):boolean
- remove(int):E
- remove(E):boolean
- size():int
Stack 类
继承自 Vector , Vector 是一个同步安全的 List
- push(E):E 入栈
- pop():E 出栈
- peek():E 查看顶部第一个元素
- search(Object):int
- empty() 是否是空的
Set 接口
- add(E):boolean
- contains(Object):boolean
- remove(Object):boolean
- size():int
Queue
- add 添加元素,返回添加结果,如果不能添加就抛出异常
- remove 删除队列头,空队列异常
- element 返回队列头,空队列异常
- offer 添加元素,返回添加结果
- poll 返回并删除队列头,空队列的话返回 null
- peek 返回队列头,空队列的话返回 null
Map 接口
- put(K, V):V
- remove(Object):V
- containsKey(Object):boolean
- containsValue(Object):boolean
- size():int
ArrayMap 和 HashMap
ArrayMap 有缓存, HashMap 没有
内存小
SparseArray 和 ArrayList
